引言
首先,让我们理清几个渲染过程的基本概念。
Pipeline
在渲染过程中,将模型空间的画面经过一系列处理,最终输出到屏幕设备上的过程即为渲染管线(Pipeline),DRP、URP、HDRP都是修改了这之间的过程。
pipeline的整个流程可以细分为如下图所示的几个阶段(图源自defold官网的教程配图):
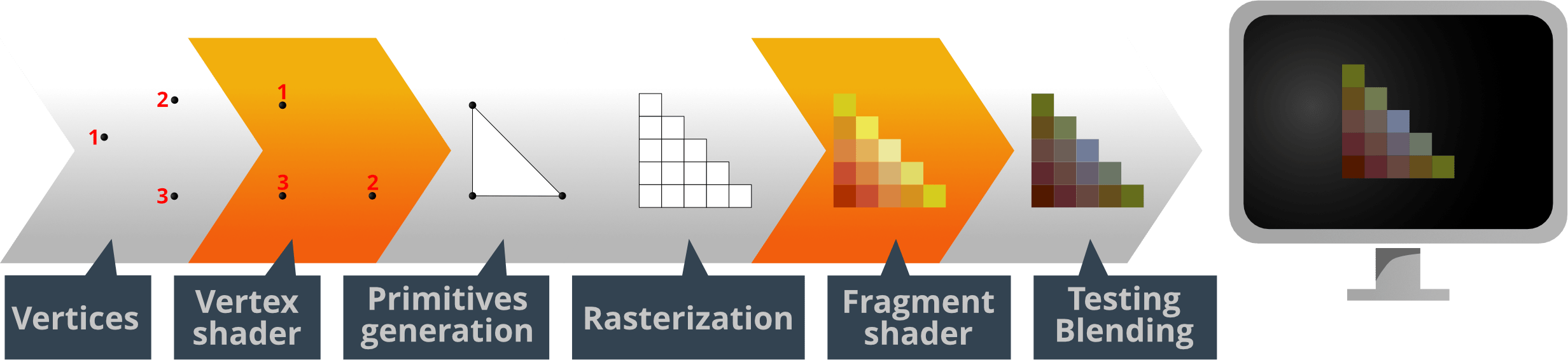
- 确立模型各面的顶点信息,包括坐标、法线、纹理坐标等
- 经过顶点着色器处理,对三角面的三个顶点的坐标进行必要的变换,以及处理光照
- 为三角面生成图元
- 光栅化,亦即将模型空间的三角面内部映射到输出设备上的像素空间。这一步可以理解为计算图元都覆盖到了哪些像素上
- 经过片段着色器(也称像素着色器)处理,对各个像素的颜色进行变换
- 输出合并
除了以上几步,在2,3之间还有可选的“曲面细分着色器”和“几何着色器”,还可能涉及到投影/裁剪的过程,不多赘述。
Drawcall 与 Batch
由于CPU和GPU的差异,CPU不仅要负责运算,还要负责指令执行、IO交互、内存管理等等,而GPU则专注于运算。因此,CPU和GPU的交互频率可能成为制约渲染性能的因素————如果CPU不能尽快地将要渲染的信息传递给GPU,就会浪费GPU的性能。
drawcall指的是CPU调用图形API去进行真实渲染的过程。因此,drawcall就涉及到了CPU与GPU的交互。不过,现代图形API会将drawcall放入CommandBuffer,然后一次将大量的drawcall任务提交给GPU,所以由drawcall导致的CPU与GPU的多次交互问题实际上已经基本解决。然而,渲染时使用的上下文信息,如Shader、材质、纹理、Render State等,如果在drawcall之间需要频繁的切换,这一过程会带来大量的性能损耗。在Unity中,这一过程称为SetPass。
因此,通常为了减少CPU与GPU之间的数据交互,我们需要尽可能地将数据打包,减少交互次数。这就是Batch(批)的概念。一个Batch通常至少包含一个drawcall。
在Unity中,可以打开FrameDebugger窗口查看帧的渲染draw命令执行情况。需要注意,里面有些操作并非drawcall。
SRP Batcher
SRP Batcher的作用: 将相同Shader variant的多个drawcall打包成一个Batch,减少CPU与GPU之间的数据交互次数。可以理解为将使用到相同渲染信息的drawcall合并到一起,减少了GPU渲染上下文切换的消耗。这使得连续的draw过程通常不涉及SetPass,从而提高了渲染性能。然而,SRP Batcher并不会减少drawcall次数。
具体的内容可以参考Unity文档给出的解释:How the SRP Batcher works
SRP Batcher可启用于URP/HDRP。
在Unity中使用DRP 启用SRP Batcher时,可能注意到Statistics界面的Saved by batching为0,这是因为Unity的性能窗口不能识别到DRP的SRP Batcher。但是,你可以比对一下同一个DRP的项目在勾选SRP Batcher之前之后的单帧渲染时间来判断SRP Batcher的效果。
Dynamic Batching
Dynamic Batching适用于很多Render Pipeline,甚至是DRP。Dynamic Batching的做法是在渲染时将相邻的使用同一材质的小的mesh组合成一个大的整体,通过此方法来显著减少drawcall数目。
Dynamic Batching已经是比较老旧的优化方案了,在DRP上效果还算显著,但其他SRP上效果一般。由于前文中提到过的,图形API现在都会对drawcall做缓存,所以通过组合mesh的方式减少drawcall数目并不能降低多少CPU与GPU的交互频率;不仅如此,还可能由于合批的过程占用了额外的计算资源反而降低效率,因此实际使用时要考虑这样做是否合理。
GPU Instancing
GPU Instancing 是一种可以单独为材质启用的特性,它允许GPU在一次draw中,绘制同一material,同一mesh的不同实例。这些不同的实例可以有其他的变换信息,但是它们必须使用同一个mesh和材质。这些信息会保存在一个数组中(存储在Constant Buffer),GPU只需要这个数组的信息就能一口气构建出同一mesh、同一meterial的多个实例。
思考:结合使用,效果就会更好吗?
well,当你看到这个标题时,我想你心里应该能猜到结论了:不!
如果优化方案是这么简单的话,就一股脑全部应用起来就行了,然而实际上它们之间甚至会互相冲突。视情况不同选择最合适的方案才是正道。
例如:SRP Batcher通过Shader变体来进行合批,而GPU Instancing则是通过mesh和meterial进行合批。如果项目中有大量的Shader变体,而有很多Object使用了相同的mesh和meterial,那么SRP Batcher的效果就会大打折扣,此时使用GPU Instancing就更合适了;相应地,如果项目中的Shader变体很少,那么SRP Batcher的效果就会很好,此时使用GPU Instancing就没有必要了。
何况,就算想同时使用它们也不行。SRP Batcher与GPU Instancing不完全兼容,同时启用SRP Batcher和GPU Instancing会导致GPU instancing只能被迫加到通常的渲染路线里,只有很少的特定情况下可以应用之。
题外话:关于多光照
以上的几种优化方案在单光源的情况下都是适用的。可如果为场景新增一个光源,DRP上的这些优化方案就不能起到完全的作用,因为DRP是比较过时的前向添加的pipeline,导致新的光照会增加pass数。对于depth和shadow pass,这些优化还算正常;但对于RenderForward.RenderLoopJob则不会生效。
不过URP/HDRP不会有这类问题:所有的光照都是在一个通道里渲染的,因此上述几类优化方案都能正确地生效。
文档信息
- 本文作者:Donkey
- 本文链接:https://bigmaddonkey.github.io/2023/05/07/unity-render-performance/
- 版权声明:自由转载-非商用-非衍生-保持署名(创意共享3.0许可证)